Memory management of the heap and stack (but mainly the heap) is (if ignoring syntax) the greater difference between the languages of C, Rust and Java. While Java isn’t per se a low-mid level language, it’s Garbage Collector feature provides insights on how one of C’s greatest problems is handled by high-level programming languages today.
Stack and Heap fundamentals
The stack and heap are two primary areas of memory management that programmers encounter when writing code. They differ fundamentally in their structure and how memory is allocated.
The Stack
The stack operates as a LIFO structure, growing and shrinking as functions are called and return, with each function invocation creating a stack frame. For example considering the code:
int add(int a, int b){
return a + b;
}
This code, when executed, will instance a stack frame onto the stack. This stack frame then contains:
- Return address (where to go after function ends)
- Parameters passed to the function
- Local variables
- Saved registers or state
When the subroutine or function finishes its execution, the stack frame is then “popped” out of the stack, and if a return is specified, that value is passed onto the caller stack frame (this happens, logically, immediately before the stack frame is popped from the stack).
The concept of scope in the stack refers to the idea that a value stored on a stack frame belongs inherently to it, being inaccessible to other frames and being deallocated once the stack frame to which it belongs is popped from the stack. The implications of this will be explored further with the concept of pointers.
The image below shows the typical layout of a process’s memory in most operating systems.
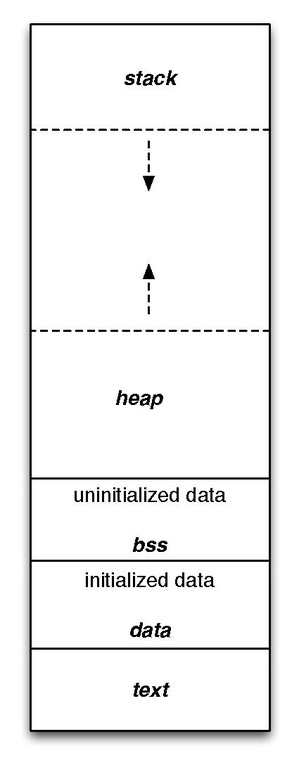
So far we have seen the concept of the stack. And earlier on I claimed that the stack and heap are the two main areas of memory. However a process will contain other areas of memory worth noting:
- Data segment: Contains initialized global and static variables.
- BSS: Contains uninitialized or zeroed static and global variables, as a record of how much zeroed memory is needed.
Meanwhile the text area (known as text segment or code segment ) will contain cleartext executable code in a read-only manner.
The Heap
The heap contains dynamically allocated memory (key concept) and typically begins where the BSS segment ends. We can manually assign or free memory from heap with C lib wrappers for syscalls such as malloc, calloc, realloc and free. This segment is shared and accessible for all threads, libraries and modules of the process.
Because the programmer can manually alter the heap, they can also make mistakes when dealing with memory, the point of this post is explaining common mistakes with C and how Rust and Java manage memory to avoid said issues.
Memory management mistakes in C
To understand the common errors in C memory management, let’s first get a grip on how C memory management is generally done.
What’s a pointer and why are they used
A pointer in C is simply a variable whose content is the memory address of another variable. This is easier to understand if we first get that a variable is (at its lowest level) a space, located by an address, which contains a value.
Let’s take for example Rust’s i32, this is a 32 bit integer. When storing a variable that’s an i32 we will have:
let numA : i32 = 1;
This is a declared variable, to be precise it’s an immutable (due to Rusts syntax) integer of 32 bits that will be stored in it’s adequate stack frame as we know it’s value before runtime (This may be a bit more nuanced as if we never change the value, the rust compiler may see it as a constant and optimize it into the data segment. This is irrelevant for our current case).
In memory, this will look something like:
0x001 : 1
Where 0x001 is the memory address of the variable and 1 it’s value.
Pointers are rarely used in Rust (as in raw pointers) per se, so let’s say we have declared this in C:
int main(){
int numA = 1;
return 0;
}
When we run this, the main function will instance a stack frame to be pushed onto the stack, it will have a variable of the integer type assigned to 1 and will return 0, indicating successful program termination.
But now imagine we also have the function:
int addOne(int num) {
num + 1;
}
int main(){
int numA = 1;
addOne(numA);
return 0;
}
In C, when we pass a variable as an argument to a function, we pass it by value. This means the function receives a copy of the variable, not a reference to the original memory address.
So how can we keep the result? There’s 2 main ways to do it:
- Returning the value
- Passing a pointer to our variable
In this case returning the value is the correct way to do it, the code would look like:
int addOne(int num) {
return num + 1;
}
int main(){
int numA = 1;
int numA = addOne(numA);
return 0;
}
But we want to understand the concept of passing by reference, so let’s explore how this is done with pointers so that we can get a general idea on how they work before we jump into cases where they are our only choice.
This is how this operation is done using pointers:
void addOne(int *num) {
*num = *num + 1;
}
int main() {
int numA = 1;
addOne(&numA);
return 0;
}
Now, when we call the function addOne(), we are passing the address of numA (using the unary & operator) as the argument. We can do this because addOne now takes a pointer to an integer (int *num) instead of a regular integer (int num). When addOne() receives the pointer to numA, it accesses the value the pointer refers to (using the unary * operator) and increments it by 1.
Disambiguation of *num = *num + 1;
- The first
*num(left side) is treated as a modifiable lvalue, meaning it refers to the memory location pointed to bynum, where a new value can be stored. - The second
*num(right side) is treated as an rvalue, meaning it represents the current value stored at the memory location pointed to bynum, which is read to compute the new value. - Even though both
*numexpressions involve the value at the location pointed to bynum, C differentiates them based on their context:- On the left side of
=,*nummeans “the place in memory to write to.” - On the right side,
*nummeans “the value stored at that memory location to read.”
- On the left side of
If we remember how the stack works, it becomes clear that addOne() has its own stack frame and was called after main(). By passing addOne() a pointer (reference) to our variable, we can access that variable even though it’s technically out of the current function’s scope.
This means we can access variables on the stack outside the current scope as long as:
- We only access variables from stack frames created before the current one (because variables in stack frames created after ours no longer exist by the time we access them).
- We have been passed a pointer to those variables.
But in this case, we used pointers mostly by choice. Now, let’s look at an example where using pointers is absolutely necessary: when working with the heap.
Let’s face a slightly more complicated scenario:
We need a function that creates an array of
nintegers (wherenis user-defined at runtime) and returns it to the caller. The array must persist after the function exits.
#include <stdlib.h>
int* create_array(int size) {
// we allocate memory on the heap for 'size' integers
int* arr = (int*)malloc(size * sizeof(int));
if (arr == NULL) {
exit(1); // handle allocation failure, good practice
}
// we initialize the array by giving it some values
for (int i = 0; i < size; i++) {
arr[i] = i * 10; // this is: [0, 10, 20, ...]
}
return arr; // return heap-allocated pointer
}
int main() {
int size = 5;
int* my_array = create_array(size);
// Use the array
for (int i = 0; i < size; i++) {
printf("%d ", my_array[i]); // 0 10 20 30 40
}
free(my_array); // deallocate heap memory
return 0;
}
Alright, so why is the heap necessary? Well, if we tried stack allocation:
int arr[size];
return arr; // this is dangerous!
Remembering how the stack works we know that arr will be destroyed when the create_array() frame is popped. This means that arr will be a pointer to invalid memory. This is our first C error: A Dangling Pointer. This causes what’s known as undefined behavior, which is either a crash or memory corruption.
So here’s the thing, by using the heap our variables now keep existing even when the frame that allocated them is popped from the stack, and we can access them as long as we have a pointer to it.
Common Errors in C
There are many reasons why we may need to use the heap. But what’s relevant to us now is noticing that we actually had to use free() to manually deallocate our variable.
This type of manual memory management creates the possibility for countless mistakes, such as:
Dangling pointers: As mentioned earlier, this occurs when a pointer refers to memory that is no longer valid.
Double frees: When we attempt to deallocate memory that has already been freed.
Memory leaks: When we lose the pointer to a heap-allocated variable, making it impossible to free that memory. The data remains allocated until the program ends, wasting resources.
These types of problems are what programmers refer to when they say that:
C allows you to shoot yourself in the foot.
Java and the higher-level fixes
Java is a high level “compiled” language (nuanced topic: compiled to bytecode - https://en.wikipedia.org/wiki/Java_bytecode)
Being a high-level language, it doesn’t allow the user to manually allocate memory, in fact, pointers don’t exist in Java, instead all primitive values are passed by value and objects by reference.
Despite being hated by a large part of the developer community, it did make the process of Garbage Collection a mainstream way of dealing with heap memory.
Please note that java was not the first language to use Garbage Collection, this was done by Lisp.
Before talking about how good Garbage Collection is (or isnt), lets first define it:
Garbage collection is an automatic memory management process used in many programming languages to simplify heap memory deallocation. It typically involves identifying and freeing memory occupied by data that is no longer reachable by the program, all without requiring explicit intervention from the programmer.
In Java, the GC works on a manner that may seem relatively unellegant, yet functional:
Java uses a tracing garbage collector, primarily a generational one, which periodically scans the heap to identify objects that are no longer reachable from any live references and then frees them. This approach means that memory isn’t always reclaimed immediately when objects become unreachable.
Java’s GC does not rely on reference counting. Instead, it uses sophisticated algorithms to handle cycles and clean up unreachable objects automatically, which avoids problems like memory leaks caused by cyclic references. However, this tracing mechanism can introduce pauses or latency, depending on the collector configuration.
An slightly more elegant solution could be Python’s reference counting. Python keeps track of the number of references to each object, and when that count drops to zero, the object is freed immediately. This can feel more “elegant” in the sense that memory is reclaimed as soon as objects become unused.
However, reference counting alone cannot handle reference cycles (Objects that reference each other but are otherwise unreachable) Python includes an additional cyclic garbage collector that periodically identifies and frees these cycles.
The Rust solution
Java and many other high level languages help us by taking the ability of handling memory away from us. But we may need or want to keep this ability. This is where the Rust language comes in.
Rust lets you manage memory safely without a garbage collector. It uses an ownership system that catches mistakes at compile time.
Ownership basics
Let’s take a look at some Rust code:
fn main() {
let s1 = String::from("hello"); // s1 owns this heap data
let s2 = s1; // ownership moves from s1 to s2
// println!("{}", s1); // !!! this would be a compile error: s1 no longer owns the data
println!("{}", s2); // this works because s2 now owns the data
}
When s1 is created, it owns the heap-allocated string data. Assigning s1 to s2 moves ownership, so s1 is invalidated and cannot be used afterward. This prevents dangling pointers, because you cannot accidentally use a variable after its ownership is moved.
But what about other errors?
- Double frees: Because ownership is unique, memory is freed exactly once. When the owner goes out of scope, Rust automatically frees memory safely (Similar to an instant Garbage Collector, or to like how stack-allocated variables work).
- Memory leaks: When the owner of a value goes out of scope, Rust automatically calls the special
Droptrait to free the associated memory immediately and safely. This deterministic cleanup means memory is freed without delays or manual intervention. Memory leaks are rare and only happen if you explicitly use functions likemem::forgetto prevent Rust from running theDropcode.
This behavior is what has made a lot of low-level developers fall in love with Rust. Let’s take a look at some other examples to further understand how the ownership system works.
Safe heap allocation in Rust
Let’s rewrite the C create_array() example safely in Rust:
fn create_vector(size: usize) -> Vec<i32> {
let mut v = Vec::with_capacity(size);
for i in 0..size {
v.push(i as i32 * 10);
}
v // ownership moves to the caller safely (this is a return in Rust)
}
fn main() {
let my_vec = create_vector(5);
for val in &my_vec {
println!("{}", val); // prints 0, 10, 20, 30, 40
} // memory freed automatically when my_vec goes out of scope
}
But wait, what’s that &my_vec? In Rust, the & symbol creates a reference to a value rather than moving ownership. When we write for val in &my_vec, we’re iterating over references to the elements inside my_vec, not taking ownership of the vector itself. This means the vector my_vec remains valid and usable after the loop, and Rust’s borrowing rules ensure that while we’re reading the elements through these references, the original data won’t be modified or dropped. Using references like this allows safe, efficient access to data without unnecessary copying or ownership transfers.
As a quick clarification, loops introduce their own scope, similar to stack frames for functions, so variables created inside them live only for the duration of the loop.
Borrowing
In C, you pass pointers to functions to modify data outside the current scope. Rust uses borrowing to do this safely, this is modifying data safely without ownership transfer.
fn add_one(num: &mut i32) {
*num += 1;
}
fn main() {
let mut x = 5;
add_one(&mut x); // mutable borrow of x
println!("{}", x); // prints 6
}
&mut i32 is a mutable reference, borrowing x temporarily. Rust enforces at compile time that no other references exist while borrowing mutably, preventing data races or use-after-free.
The Borrow-Checker
This is Rust’s compile-time system that enforces its ownership and borrowing rules to ensure memory safety. It tracks how references (borrows) to data are used throughout the program and makes sure you never have dangling references, data races, or simultaneous mutable and immutable borrows. Essentially, it guarantees that:
- You can have many immutable references to a value at once,
- Or exactly one mutable reference,
- But never both at the same time.
By enforcing these rules, the borrow checker prevents common bugs like use-after-free, null pointers, and race conditions.
This all makes Rust one of the most loved languages in 2025.